
Juli 23, 2020
Wissenswertes über die robots.txt ✅

Bildquelle: Pixabay
Die Robots.txt
Wer eine Website betreibt und korrekt von den Suchmaschinen gecrawlt und indexiert werden möchte, muss eine robots.txt auf dem Root-Pfad der Domain liegen haben. Diese muss natürlich auch korrekt konfiguriert werden. Der Rootpfad ist immer dort, wo die Index-Datei für die Startseite der Website liegt. Genau in diesem Stammverzeichnis muss auch die robots.txt liegen.
Diese kleine Textdatei sieht zwar unscheinbar aus, aber sie ist trotzdem wichtig. Darin lassen sich Anweisungen für die Suchmaschinen-Crawler geben. Z.B. kann man den Suchmaschinen verbieten bestimmte Verzeichnisse zu crawlen. Das ist besonders wichtig, wenn sich in diesen Verzeichnissen Inhalte befinden, die auf keinem Fall im Index der Suchmaschinen landen sollen.
Mir ist es mal vor Jahren passiert, dass ich auf meinem Server eine Website für einen Kunden erstellt hatte und vergaß, dieses Verzeichnis für die Suchmaschinen zu sperren. So geschah es, dass ich mit der neuen Seite auf meinem Server besser rankte als die alte Website vom Kunden auf seiner Domain. So etwas sollte nicht passieren.
An die Vorgaben der Robots halten sich im Allgemeinen die meisten Suchmaschinen, jedoch nicht alle. Es gibt auch Exoten, denen interessiert die Robots gar nicht. Selbst wenn man diese Suchmaschinen, sogenannte User Agents, total aussperrt, dann indexieren die trotzdem alles, was sie finden.
Wer mit SEO-Tools vertraut ist, weiß auch, dass es meistens die Option gibt „folge den Anweisungen der robots.txt“. Dann verhält sich die Software so, wie z.B. Googlebot, der Crawlerbot von Google. Google und Bing halten sich auf jeden Fall an die Anweisungen der robots.txt.
Die kleinen Datensätze der robots.txt nennt man Records. Diese Records sind in zwei Teilen gegliedert. Der erste Teil benennt den User Agent für den der zweite Teil, worin die eigentlichen Anweisungen enthalten sind, gelten soll. So kann man bestimmten Suchmaschinen Zutritt zu Verzeichnissen gewähren und anderen das verbieten. Da es sehr viele Suchmaschinen gibt und niemand wirklich alle kennt, wird häufig ein Sternchen (*) verwendet. Das bedeutet, dieser Record gilt für alle. Wir kennen aus Windows oder Linux die Sternchen als Wildcards und diese Funktion übernimmt ein Sternchen hier auch.
Ich zeige euch hier mal den grundsätzlichen Aufbau einer robots.txt
User-agent: User Agent 1
User-agent: User Agent 2
Disallow: /pfad/zum-Verzeichnis/privat
Mit diesen Records verbieten wir den User Agents 1 und 2 das indexieren bzw. das Crawlen des Verzeichnisses „privat“. Der Wert „Disallow“ bedeutet „hier darfst du nicht rein“ für den betreffenden Suchmaschinen-Bot.
Möchte man dasselbe Verzeichnis global für alle Suchmaschinen sperren, dann sähe der Record so aus:
User-agent: *
Disallow: /pfad/zum-Verzeichnis/privat
In diesem Fall sind die Verzeichnisse oberhalb von „privat“ noch indexierbar. Diese sind nicht vom „Disallow“ betroffen.
Man kann jedes X-beliebige Verzeichnis auf diese Art von der Indexierung ausschließen.
Gerade bei sehr bekannten CMS, wie Typo 3, Joomla, Drupal, Contao, WordPress usw. ist es sehr ratsam, bestimmte Systemverzeichnisse von der Indexierung auszuschließen. Diese genannten Systeme liefern per default immer eine bereits vorkonfigurierte robots.txt mit. Jedoch befinden sich auf den meisten Domains auch Verzeichnisse außerhalb des verwendeten CMS (Content Management System). Hier könnten Verzeichnisse liegen, wo sich Dinge drin befinden, die man nicht bei Google und Co. finden möchte.
Es gibt auch nicht selten z.B. Vereins-Websites, die wollen gar nicht bei Google gefunden werden und entsprechend würde es dort angebracht sein, für alle Suchmaschinen alle Verzeichnisse zu sperren.
Das Wort Sperren ist hier nicht wörtlich zu nehmen, weil, wie ich sagte, die Regeln der robots.txt einfach ignoriert werden können.
Wie es das „Disallow“ gibt, gibt es auch das „Allow“ als Anweisung. Manche Webmaster haben das bis ins kleinste Detail durchkonfiguriert und erlauben, aus welchen Gründen auch immer, bestimmten Suchmaschinen mehr als anderen.
Das könnte dann so aussehen:
User-agent: Alexabot
Allow: /videos
User-agent: Bingbot
Disallow: /videos
Hier wird nur dem Alexabot erlaubt das Verzeichnis „videos“ zu indexieren, dem Bingbot hingegen ist das untersagt.
Neben den Records für die User Agents und den Regeln für die Verzeichnisse sollte sich auf jeden Fall der Link zur sitemap.xml auch in der robots.txt befinden. Sehr große Websites verwenden oft mehrere Sitemaps. Diese werden natürlich auch mit in die robots.txt aufgenommen. Das sieht dann so aus.
Sitemap: URL der Domain/sitemap.xml
Als sehr nützlich kann es sich erweisen CSS und Javascript explizit und proaktiv auch für die Indexierung freizugeben und in der robots.txt zu erwähnen.
Viele Webmaster kennen das Problem mit den blockierten Ressourcen. Google meckert hier oft herum, dass Ressourcen blockiert sind und nicht ordentlich gerendet werden können. Früher hat Google einfach alles indexiert und gerendet. Heute verhält sich Google in etwa nach dieser Regel: Alles was nicht explizit erlaubt ist, ist verboten. Deswegen bewirkt die Freigabe von CSS und JS einiges.
Wollen wir CSS und JS global für das Rendern der Bots freigeben, brauchen wir nur diese 2 kleinen Snippets in die robots.txt eintragen.
Allow: *.css
Allow: *.js
Hier legen wir also fest: Alle Suchmaschinen dürfen CSS und JS zum rendern verwenden und indexieren. Die eigentlichen Stylesheets und Scripte werden natürlich nicht indexiert. Hier sind die Suchmaschinen schon so intelligent und können Content und Funktion trennen.
Es gibt ja nicht wenige Websites, wo der Content erst durch Scripte generiert wird und ohne CSS kann keine Website ordentlich gerendert werden.
Übrigens, wer es noch nicht wusste, Googlebot verwendet zum Rendern der Websites den Chrome-Browser, der ja von Google selbst entwickelt wurde.
Kommen wir zum Schluss. Ich zeige hier eine Demo robots.txt, wie diese final aussehen könnte.
User-agent: *
Disallow: /administrator/
Disallow: /bin/
Disallow: /cache/
Disallow: /cli/
Disallow: /components/
Disallow: /includes/
Disallow: /installation/
Disallow: /language/
Disallow: /layouts/
Disallow: /libraries/
Disallow: /logs/
Disallow: /modules/
Disallow: /tmp/
Disallow: /test/
Disallow: /ton/
Disallow: /teamwork/
Disallow: /livechat/
Disallow: /artwork/
Disallow: /entwuerfe/
Disallow: /def/
User-agent: Alexabot
Allow: /
Sitemap: URL Deiner Domain/sitemap.xml
#Googlebot
User-agent: Googlebot
Allow: *.css
Allow: *.js
Dem User-Agent Alexabot ist in diesem Fall alles erlaubt, was natürlich Schwachsinn ist, aber für unsere Zwecke gut veranschaulicht, wie es funktioniert mit der Robots. Für alle Suchmaschinen sind alle Verzeichnisse gesperrt, für die es eine Disallow-Regel gibt.
Ich habe oben gesagt, dass ein Sternchen immer für alle gilt. Das ist korrekt, wird aber trotzdem aufgehoben, wenn ein User Agent namentlich genannt wird und eine Erlaubnis folgt, was ja hier der Fall ist:
User-agent: Alexabot
Allow: /
Dann muss ich noch hinzufügen, dass, wenn ein Verzeichnis gesperrt ist, diese Regel an alle anderen Verzeichnisse innerhalb des gesperrten Verzeichnisses vererbt wird. Haben wir z.B.
Disallow: /entwuerfe/
Dann wäre
Disallow: /entwuerfe/nummer1
überflüssig, weil das Verzeichnis „nummer1“ die Regel von „entwuerfe“ erbt. Das gilt auch für „Allow“ nur eben in die andere Richtung.
Allow: /entwuerfe/nummer1
Allow: /entwuerfe
Wenn „nummer1“ erlaubt ist, kann „entwuerfe“ nicht verboten sein und ist auch erlaubt, weil der Bot durch „enwuerfe“ hindurch muss, um an „nummer1“ zu kommen. Hier wäre demnach die zweite Zeile auch überflüssig.
Wenn ihr euch die jeweilige Robots von einer Website ansehen wollt, diese liegt immer auf dieser URL:
https://www.domain-name.com/robots.txt
Teil 2

Bildquelle Pixabay
Die Robots.txt Spezial
Wie ich im ersten Beitrag zur Robots geschrieben habe, ist diese kleine Textdatei ziemlich mächtig.
Heute möchte ich auf weitere Besonderheiten eingehen, die ich im ersten Teil nicht erwähnt hatte. Nach meiner Erfahrung liegt die durchschnittliche Aufmerksamkeitsgrenze beim Lesen eines Artikels bei fast genau 1000 Zeichen. Der letzte Beitrag hatte diese Zeichenlänge schon überschritten.
Jetzt fragt ihr euch sicher, wie ich so etwas wie die Aufmerksamkeitsgrenze vom Lesen ermitteln kann. 100% genau lässt sich das nicht ermitteln. Ich habe jedoch auf sehr vielen Kundenseiten Heatmaps zur Verfügung. Diese zeigen mir, wo sich die Maus auf einer Website am häufigsten aufhält. Hat man hier umfangreichere Daten von einigen 10K Sessions zur Verfügung, dann kann man sehr gut schlussfolgern, dass bei langen Beiträgen, über 1000 Zeichen, der untere Bereich der Beitragsseiten weniger von der Maus frequentiert wird. Hier seht ihr eine typische Heatmap:
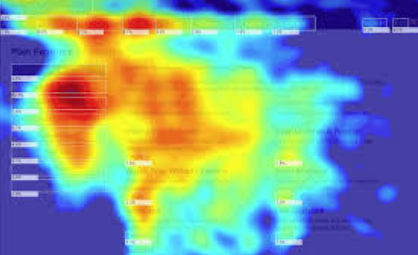
Die roten Bereiche, sind besonders stark frequentiert. Bei tiefem Rot ist die Konzentration der Mausbewegung in diesen Bereichen am größten. Bei langen Artikelseiten ist es ziemlich gut zu sehen, dass die „Maus-Berührung“ mit der Website, nach unten hin stark abnimmt. Die Heatmap ist demnach eine Art visualisierte Darstellung der Interaktions-Frequenz eines Besuchers mit der Website. Immerhin muss bei längeren Artikeln oft gescrollt werden und diese Berührungspunkte hinterlassen Daten auf der Heatmap.
Zurück zur Robots. Neben den genannten Funktionen des Sperrens oder Erlaubens von Verzeichnissen für spezielle Suchmaschinen-Bots, kann diese kleine Textdatei noch mehr. Wir können z.B. der Suchmaschinen eine kleine Verzögerung mitteilen, eine Zeitspanne, die der Bot warten soll, bevor er anfängt die Seiten zu crawlen. Dieser Befehl sieht so aus:
Crawl-delay: 5
Das sagt dem Suchmaschinenbot, „warte 5 Sekunden ab, bevor du crawlen kannst“. Eine kurze Verzögerung kann gerade bei langsameren Website Sinn machen. Nach meiner Erfahrung sollte ein Delay nicht länger als 15 Sekunden betragen. Einige Crawler sind sonst angepisst und verschwinden ganz schnell wieder.
Wer entweder eine sehr langsame Website (bedingt meistens durch den Hoster) hat, oder wer eine sehr umfangreiche Website (Startseite) hat, der sollte auf jeden Fall ein Delay in die Robots eintragen. 5 oder 10 Sekunden haben sich hier sehr bewährt. Einige Webmaster berichten davon, dass nach dem Einfügen eines Delays der organische Traffic einbrach. Deswegen sollte man darauf ein Auge werfen. Meine Erfahrungen sind nicht immer überall gültig 😊. Wenn ich von großen umfangreichen Seiten rede, meine ich Websites oder Landingpages, die größer als 3 MB sind. Das hört sich nicht viel an, aber im Zeitalter des „Mobil first“ sind 3 MB eine Menge. Mein Tipp:
haltet die Startseiten schlank.
Auf Unterseiten kann man sich austoben, aber die Startseite einer Domain muss von allen Pages am besten performen und dazu muss diese zwingend schlank sein.
Würde der Crawler sofort auf einer sehr umfangreichen oder langsamen Website los crawlen, könnte das unschöne Nebeneffekte haben. So kommt es nicht selten vor, dass in den SERPs (das sind die Suchmaschinen-Ergebnis-Seiten, Englisch: Search engine result pages) unschöne Effekte zu sehen sind. Das können abgebrochene Meta-Angaben sein, aber meistens falsch dargestellte Rich snippets. Die Crawler und Bots von den Suchmaschinen haben meistens eine extreme Performance. Hat die Website sehr viele Server-Ressourcen zur Verfügung und passiert da ständig etwas Neues, kommen die Bots auch gerne in mehreren Instanzen vorbei. Ich könnte mir vorstellen, dass hier auf Steemit ständig ein Googlebot unterwegs ist.
Ein besonderes Schmankerl der robots.txt ist, dass man neben Verzeichnissen auch bestimmte Datei-Extensionen von der Indexierung ausschließen lassen kann. Davon machen sehr wenige Gebrauch. Ich denke, die meisten wissen das gar nicht.
Möchte man z.B. Verhindern, dass Bilder von der eigenen Website indexiert werden, kann man das den Bot über die robots.txt mitteilen. Die Syntax dazu ist sehr simpel. Selbst wenn es keine Image-Sitemap gibt, wird Google und Co. immer auch die Bilder einer Website indexieren. Deswegen sind Sitemaps nicht zwingend, aber sie zeigen den Suchmaschinen an, dass die Regeln verstanden werden. Ist keine Sitemap vorhanden, dann hangelt sich der Bot durch die Links einer Website und verfolgt alles was er bekommen kann und indexiert es dann auch. Ist eine Sitemap (xml) vorhanden, dann folgt der Bot genau der darin vorgegebene Struktur.
User-agent: *
Disallow: /*.jpeg$
Disallow: /*.jpg$
Disallow: /*.gif$
Disallow: /*.png$
Disallow: /*.bmp$
Ist das in unsere robots.txt eingetragen, sagt das unserem Suchmaschinenbot, er darf keine Dateien mit den Endungen jpeg, jpg, gif, png und bmp in den Index aufnehmen, egal auf welchem Pfad sich diese befinden. Das funktioniert mit allen Datei-Endungen. Das $ sagt dem Bots, dass nach der Datei-Endung nichts mehr folgt. Wenn doch etwas folgt, ist es nicht verboten.
Eine weitere Besonderheit ist der Ausschluss von Parameter-URL. Gerade bei Shop-Systemen kommen solche dynamischen URLs nicht selten vor.
In dynamischen Parameter-URLs kommt immer ein Fragezeichen (?) vor. Damit Crawler solche URLs nicht verfolgen und eben auch nicht indexieren können, verwenden wir folgende Anweisung in der robots.txt.
User-agent: *
Disallow: /*?
Das bedeutet: Hallo an alle Bots, ihr dürft keinen URLs folgen in denen ein ? enthalten ist.
Achtung, wer noch eine ältere Website mit keiner SEO-freundlichen URL-Struktur oder wer bei WordPress die einfache Permalink-Struktur verwendet, darf diesen Parameter in der robots.txt nicht verwenden, andersfalls sperrt er die komplette Website von der Indexierung aus.
Wie wir gesehen haben, sind die kleinen Dinge oft viel wichtiger als angenommen. Die robots.txt korrekt zu behandeln gehört praktisch zum guten Ton eines Webmasters. Suchmaschinen und hier besonders Google und Bing, wissen es zu schätzen, wenn der Webmaster weiß, was er tut. So streng Google auch sein mag, wer den Regeln folgt, wird belohnt.
© Wolfram Consult GmbH & Co. KG

